sp_MSforeachdb is an undocumented system stored procedure that lets you iterate through all databases on an … sp_MSforeachdbRead more

sp_MSforeachdb is an undocumented system stored procedure that lets you iterate through all databases on an … sp_MSforeachdbRead more
Want to know the disk space available on your database server from T-SQL? This can be … An alternative to xp_fixeddrivesRead more

When a database is created, the logged in user is set as the database owner as … Changing the database ownerRead more

Are you managing a lot of SQL Server instances? I was setting up a standardized set … Script to configure SQL Server AlertsRead more
In SQL Server Management Studio, it is possible to execute a multi server query against several … Multi Server QueryRead more

When SQL Server evaluates if an index should be used to retrieve data in a query, … Index selectivityRead more
When you submit a query to SQL Server – before the query is executed – SQL … SQL Server Join MethodsRead more
Windows environment variables are a great way to store server specific information that may be accessed … Add and edit Windows environment variablesRead more
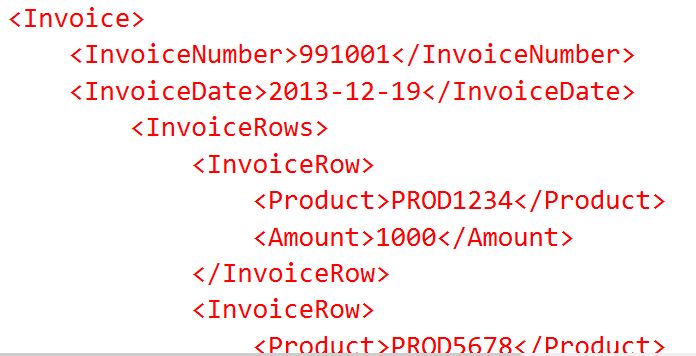
A XML document is hierarchical. A value gets meaning from its position in the document. Nodes … Using XQuery to insert a XML hierarchy into parent / child tablesRead more