If you insert lots of rows into a table with a clustered index, a SELECT COUNT(*) statement on the destination table can initially show 0 (or remain unchanged) for a long time.
This is because the rows needs to be sorted before the actual insert starts.
The following example make use of the function “GetNums”. Get it here.
A table, T1, is created and ten milion rows are inserted. The table has two columns, the first a integer used as primary key. The second column is a varchar column with a GUID value that will represent unsorted data.
CREATE TABLE T1 (PKCOL INT PRIMARY KEY CLUSTERED, GUIDCOL VARCHAR(50)); INSERT T1 SELECT I, NEWID() FROM dbo.GetNums2(10000000)
Next, we will create yet another table, T2. Basically it is the same as T1, but this time the clustering column will be the GUID column. This means that SQL Server will keep the rows ordered.
CREATE TABLE T2 (PKCOL INT, GUIDCOL VARCHAR(50) PRIMARY KEY CLUSTERED);
Now prepare an insert statement that will insert all rows from T1 to T2, but don’t execute yet::
INSERT T2 SELECT * FROM T1;
Open a new connection window and prepare the following statement:
SELECT COUNT(*) FROM T2 WITH (NOLOCK);
Now execute the first statement, and directly after that the second statement. Run the second statement a couple of times to verify that it is 0, until after a while it starts to increase.
What happens is that the rows to be inserted are sorted before they are inserted to the destination table, T2:

When there are many inserted rows, the COUNT(*) of the destination table can remain unchanged for a long time, waiting for the sort to finish. So if you ever wonder why your insert statement runs, but seemingly doesn’t insert any rows, this is a probable cause.
Depending on the amount of available memory you may get an sort warning, meaning that SQL Server uses tempdb to sort the rows on disk instead of using memory only:

Using tempdb will further slow down the insert.
If the rows are pre sorted before the insert, SQL Server realises this and skips the sort operator. The statement below creates a new table T3, which is exactly the same as T2. This time we will instead use T2 as the source. The rows in T2 are already sorted due to the clustered index:
CREATE TABLE T3 (PKCOL INT, GUIDCOL VARCHAR(50) PRIMARY KEY CLUSTERED); INSERT T3 SELECT * FROM T2;
As you can see in the executing plan, there is no sort operator:
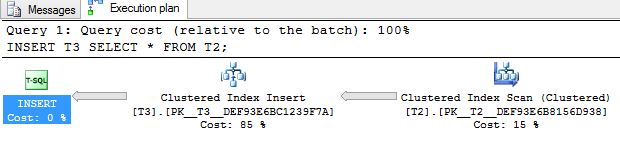
Of course, the pre sorted inserts executes much faster. 1 min 2 sec instead of 1 min 31 sec when sorting is needed (measured on my laptop).
To clean up, run the following:
DROP TABLE T1; DROP TABLE T2; DROP TABLE T3;